[Guest post cross-posted from Ihub Research. About the author: Angela Crandall studies the uptake and increasing utility of ICTs in East Africa from a user’s perspective. Angela is currently a Research Manager at iHub and also co-lead of Waza Experience, an iHub community initiative aimed at prompting under-privileged children to explore innovation and entrepreneurship concepts grounded in real-world experience.]
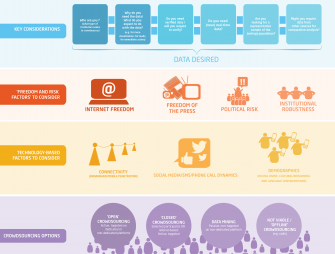 iHub Research is pleased to publish the results of our research on developing a Crowdsourcing Framework for Elections. Over the past 6 months, we have been looking at a commonly held assumption that crowdsourced information (collected from citizens through online platforms such as Twitter, Facebook, and text messaging) captures more information about the on-the-ground reality than traditional media outlets like television and newspapers. We used Kenya’s General Elections on March 4, 2013 as a case study event to compare information collected from the crowd with results collected by traditional media and other sources.
iHub Research is pleased to publish the results of our research on developing a Crowdsourcing Framework for Elections. Over the past 6 months, we have been looking at a commonly held assumption that crowdsourced information (collected from citizens through online platforms such as Twitter, Facebook, and text messaging) captures more information about the on-the-ground reality than traditional media outlets like television and newspapers. We used Kenya’s General Elections on March 4, 2013 as a case study event to compare information collected from the crowd with results collected by traditional media and other sources.
iHub Research is pleased to publish the results of our research on developing a Crowdsourcing Framework for Elections. Over the past 6 months, we have been looking at a commonly held assumption that crowdsourced information (collected from citizens through online platforms such as Twitter, Facebook, and text messaging) captures more information about the on-the-ground reality than traditional media outlets like television and newspapers. We used Kenya’s General Elections on March 4, 2013 as a case study event to compare information collected from the crowd with results collected by traditional media and other sources.
The three main goals of this study were to:
1) test the viability of passive crowdsourcing in the Kenyan context, 2) to determine which information-gathering mechanism (passive crowdsourcing on Twitter, active crowdsourcing on Uchaguzi, or online publications of traditional media) produced the best real-time picture of the on-the-ground reality, and 3) to develop a framework to help aspiring crowdsourcers to determine whether crowdsourcing is viable in their context and if so, which techniques will offer verifiable and valid information.Download the Final Report here. Download the 3Vs Crowdsourcing Framework here. Download the 3Vs Framework Visual here.